Unity 6から正式サポート予定の機械学習パッケージであるUnity Sentisを試用してみました。試作したUnityプロジェクトはGithubで公開しています。
https://github.com/TomohikoMukai/SentisTest
Unity Sentisとは?
Unity Sentisとは、学習済みのAIモデルをUnityランタイム上で実行するための機能です。正確にはONNX形式でエクスポートされた学習済み機械学習モデルをUnityで実行させるための仕組みであり、Unityランタイム内でのモデル学習はサポートしていません。また執筆時点では、PyTorchあるいはTensorFlorwにより構築された機械学習モデルのみがサポートされています。つまりscikit-learnなどの他パッケージで提供されている広義の機械学習手法(サポートベクタマシンやランダムフォレストなど)は利用できません。あくまでPyTorch/TensorFlowで自作&訓練済のニューラルネットワークをUnityで動作させるための機能ですが、それだけでも非常に強力かつ広い可能性を持つため、今回はその動作確認を兼ねて試用してみました。
以降、まずUnityにSentisを導入するための手順を簡単に紹介した後、Unityの出力画面を対象とした簡単な識別器の構築とテスト方法を説明します。
Unityプロジェクトの設定
Sentisプレビュー版はUnity 2023.2以降でのみ利用可能です。今回は2024/2/8時点の最新バージョンであるUnity 2023.2.8f1を利用します。そしてテスト用に SentisTestと命名した3D URPプロジェクトを作成します。
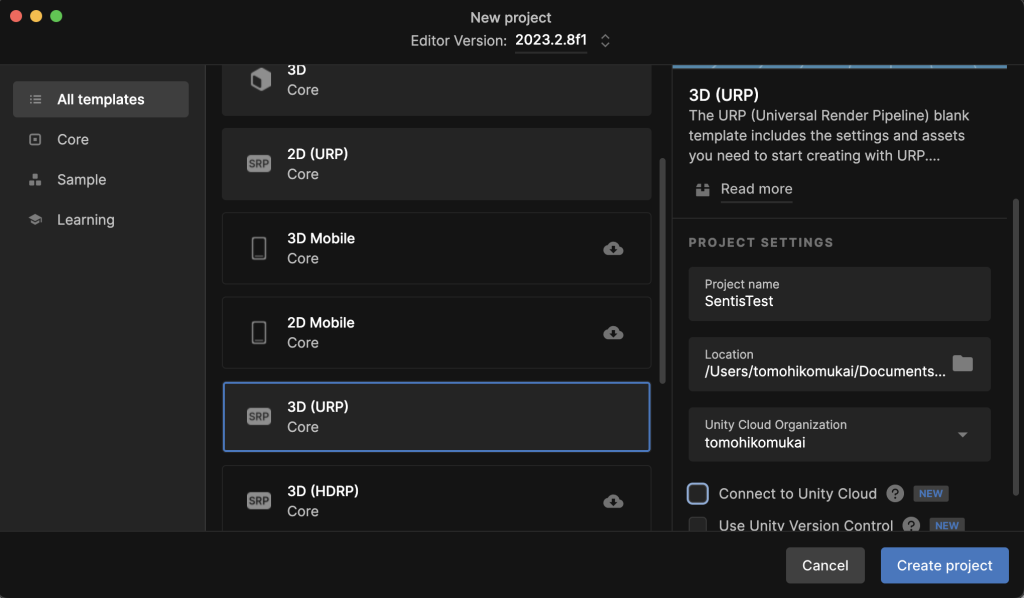
続いてSentisパッケージをプロジェクトに追加します。Project Managerを開き、左上のプラス(+)マークから、「Install package by name… 」を選択します。
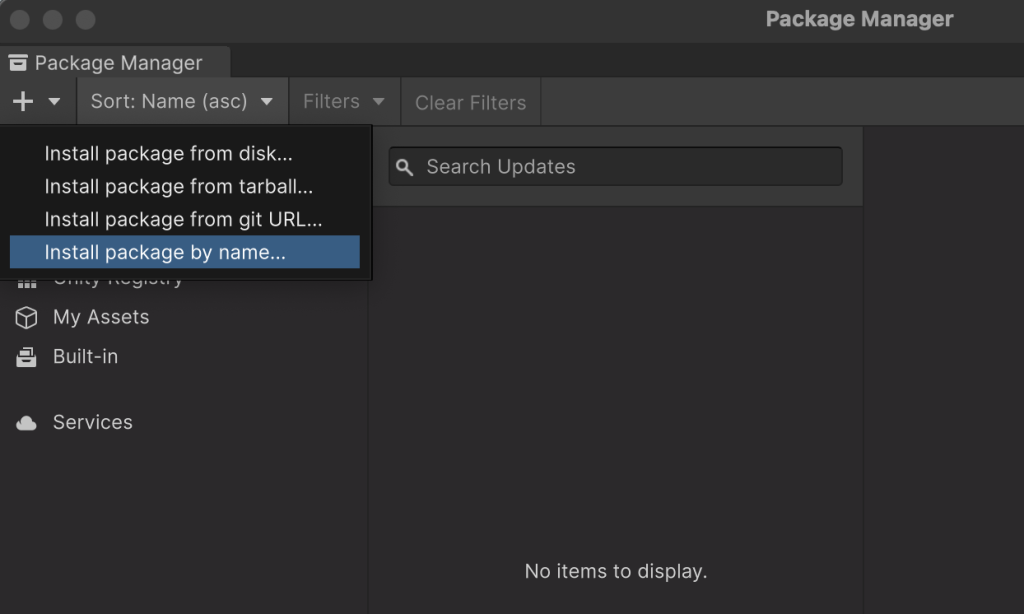
上段のテキストボックスに「com.unity.sentis」と入力し、Installボタンを押します。
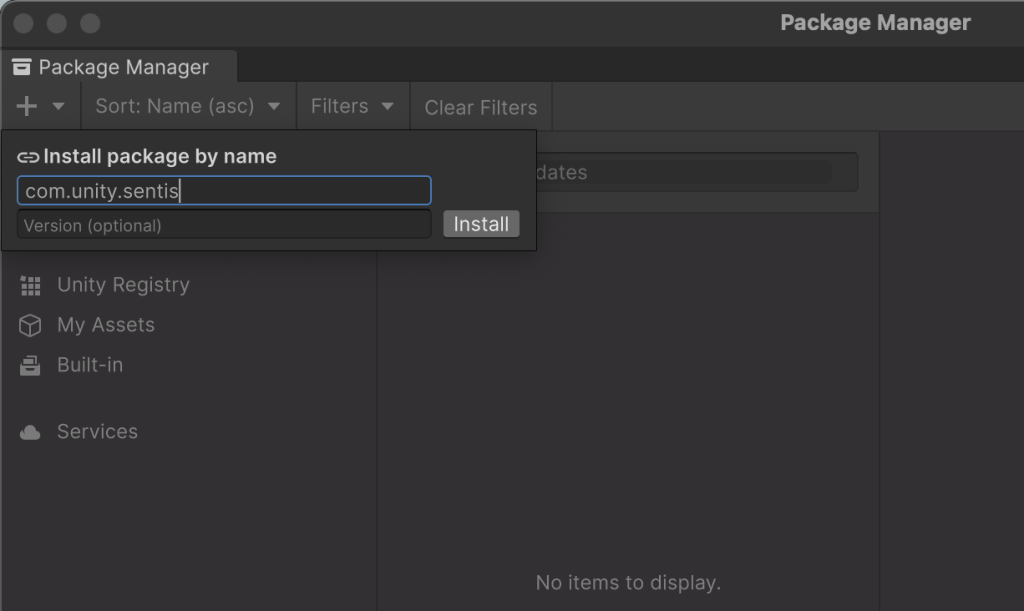
成功するとSentisパッケージが In Projectの一覧に表示されます。以上がUnity Sentisを利用するための準備です。
立方体検出器の構築
簡単な機械学習モデルとして立方体検収器を制作します。この検出器は画面内にある1つの立方体の全体が表示されているときにTrue、立方体の一部でも欠けて表示されているor全て表示されていないときにFalseを出力する二値分類器として構築します。その際、検出器を学習するための訓練データの出力、および訓練済みモデルの実行・テストはUnityに実装します。一方、訓練データを用いた学習機構はPyTorchを用いて実装します。
1. 訓練データの生成
はじめにUnity上で訓練データを生成し、PyTorchから利用できる形式で出力します。今回の検出器の学習に必要なデータは、3Dシーンのレンダリング画像と、画像内に立方体全体が表示されているか否かを示す二値データのペアです。こうした多数のペアデータをカメラをランダムに動かすことで自動生成します。
まず始めに、Gameウィンドウのアスペクト比を1:1つまり正方形に設定します。下図では10:10にしてしまってますが、シーンが正方形に表示されていれば問題ありません。
次に、適当な立方体を用意します。検出テストをしやすいよう、立方体のベースカラーは真っ赤にしておきます。この立方体を各辺の長さを5に拡大して原点に配置します。一方、メインカメラはデフォルト位置 [0, 1, -10]のまま配置し、立方体を正面から捉えるように設定します。
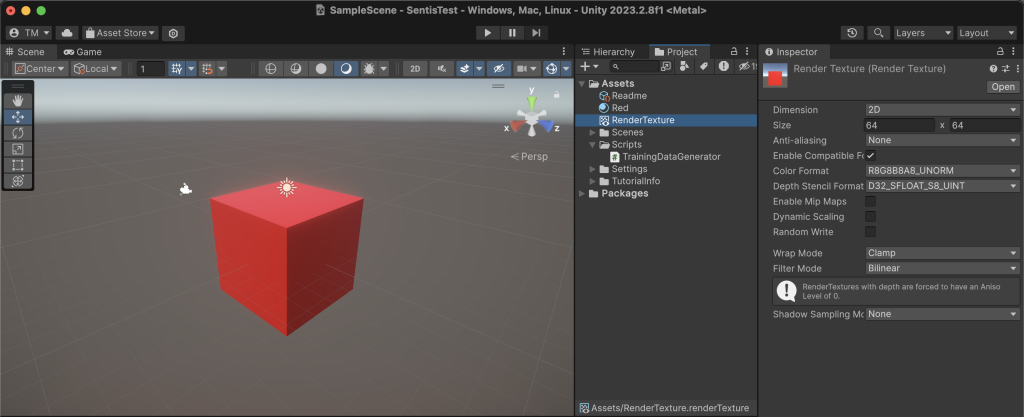
続いて、シーンのレンダリング結果を格納するRenderTextureを作成します。Unityメニューの[Assets]–>[Create]–>[Render Texture]で生成し、適当な名前(下図ではRenderTexture)に変えておきます。さらにニューラルネットの学習を効率化するために、RenderTextureのSizeを64×64に縮小します。その他の設定はデフォルトのままで、Color FormatはRGBAの4成分を含んでいます。
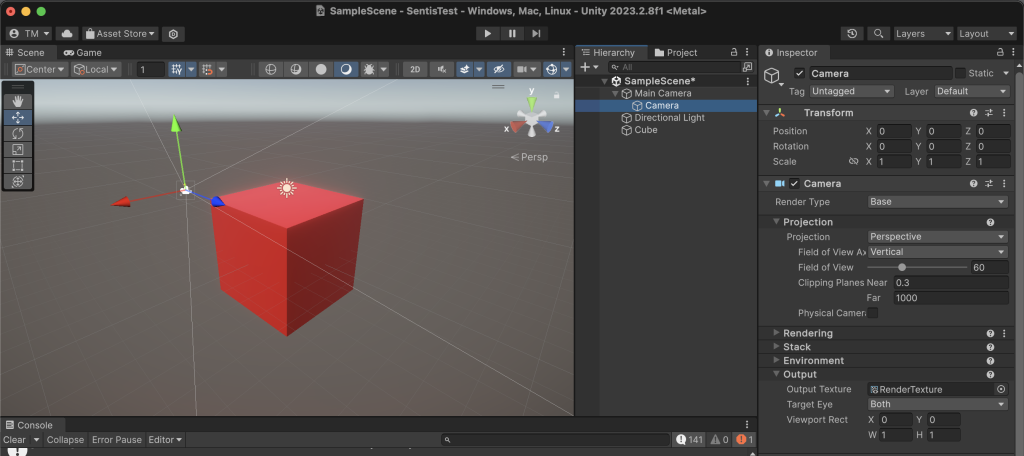
そして、RenderTextureにシーンのレンダリング結果を出力するための設定を行います。まず新しいカメラを追加し、下図のようにMainCameraの子要素にします。子カメラの位置や回転は全て0にすることで、MainCameraと同じレンダリング結果を得るように設定します。このとき、2つのカメラのProjection設定が同一であることも念のために確認しておきます。うまくいくと、RenderTextureのインスペクタに表示される画像(つまりRenderTextureに保存されているレンダリング画像)と、Gameウィンドウに表示されるレンダリング結果が一致するはずです。
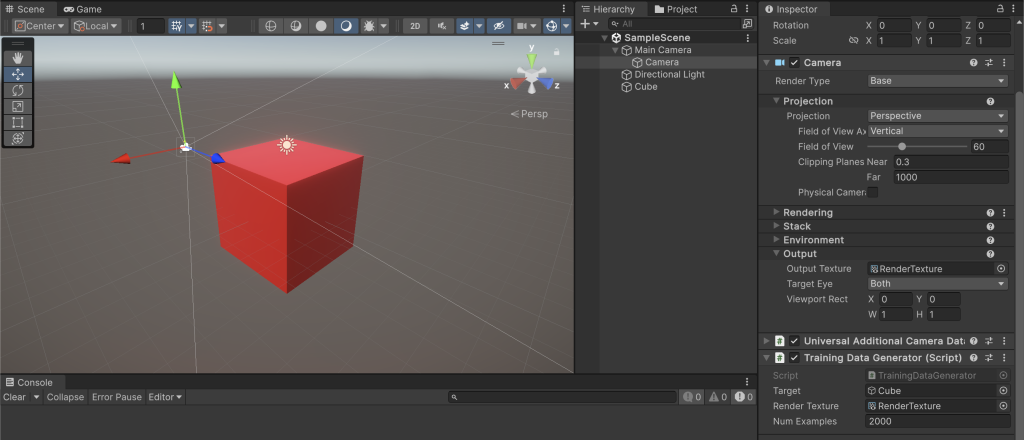
最後に、子カメラに訓練データ生成スクリプト:TrainingDataGenerator.csを加えます。そして、インスペクタに表示されるTargetに立方体オブジェクトを、Render TextureにRenderTextureを、Num Examplesに生成したい訓練データ数を指定すれば準備完了です。
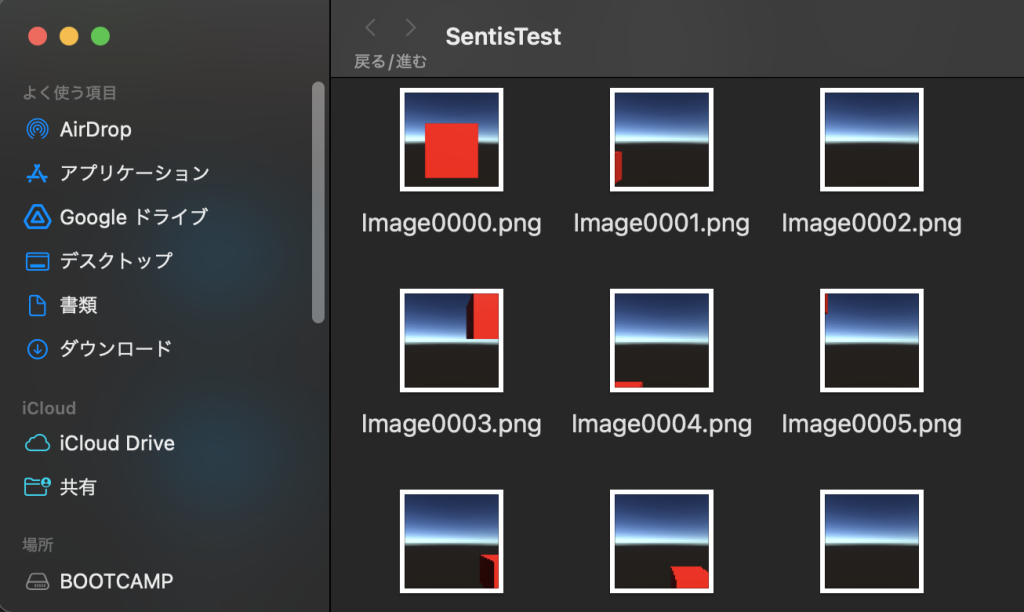
以上の作業の完了後にシーンを再生すると、Unityプロジェクトフォルダ直下にImageXXXX.png(XXXXは連番)とVisibility.csvというファイルが出力されます。前者の画像データがレンダリング画像、Visibility.csvの各行が各画像における立方体の可視状態を1 or 0で格納しています。
2. 検出器の学習
生成された訓練データを用いてPyTorch上で学習を行います。今回は sentis.ipynb に示すように、畳み込み層やプーリング層、全結合層を適当に組み合わせて検出ネットワークを構成しています。下記に検出器本体のPyTorchコードを抜粋して掲載します。このネットワークに対してbinary cross entropyロスを最小化するように適当なoptimizerを用いて学習することで検出器を構築します。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | class Detector(nn.Module): def __init__(self, im_size, in_channels, num_hiddens): super(Detector, self).__init__() # プーリング層を介して2つの畳み込み層を設定 self.conv1 = nn.Conv2d( in_channels=in_channels, out_channels=num_hiddens//2, kernel_size=3, stride=1, padding=1) self.pool1 = nn.MaxPool2d( kernel_size=3, stride=3) self.conv2 = nn.Conv2d( in_channels=num_hiddens//2, out_channels=num_hiddens, kernel_size=3, stride=1, padding=1) # 全結合層への入力次元数を計算 nfeatures = np.floor((im_size - 1) / 3.0 + 1) #conv1 nfeatures = np.floor((nfeatures - 3) / 3.0 + 1) #pool1 nfeatures = int(nfeatures) * 3 nfeatures = num_hiddens * nfeatures * nfeatures # 全結合層2つを通じて出力 self.linear1 = nn.Linear(nfeatures, nfeatures // 2) self.linear2 = nn.Linear(nfeatures // 2, 1) def forward(self, inputs): z = inputs[:, 0:3, :, :] # remove alpha channel z = self.conv1(z) z = F.relu(z) z = self.pool1(z) z = self.conv2(z) z = torch.flatten(z, 1) z = self.linear1(z) z = F.relu(z) z = self.linear2(z) return F.sigmoid(z) # nn.BCELossを用いるためsigmoidを利用 |
なお、こちらをGoogle Colaboratory上で学習させるのが簡便と思いますが詳細は割愛します。なお、Colaboratory上で実行する際には !pip install onnx の1行を加えてonnxモジュールを追加インストールする必要があります。
そして学習済みモデルをtorch.onnx.export関数を用いてONNXファイルに出力します。使用例は次の通りです。詳細はUnity SentisのマニュアルおよびPyTorchマニュアルを参照してください。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | import onnx # 出力するモデルの設定 model = Detector( im_size=64, in_channels=3, num_hiddens=6).to(device) checkpoint = torch.load('sentis_weights.pth') model.load_state_dict(checkpoint) # onnxファイルへの出力 onnx_file = 'sentis.onnx' torch.onnx.export( model=model, args=torch.randn((1, 4, 64, 64)), # 入力値ダミー f='sentis.onnx', # モデル名 opset_version=15, # Sentis1.3ではopsetバージョンは15に設定 export_params=True, # 必ずTrue do_constant_folding=True, # True/Falseどちらでもよい(はず) input_names=['inputs'], # 入力テンソルは1つ output_names=['output'], # 出力テンソルも1つ |
3. Unity Sentisを用いた学習済みモデルの実行
PyTorchからエクスポートされたONNXファイルをUnityで読み込み、学習済みモデルを用いた推論を行う手順を説明します。ここでは訓練データ生成時に用いたものと同じUnityプロジェクトおよびシーンを拡張することで推論テストを実装します。
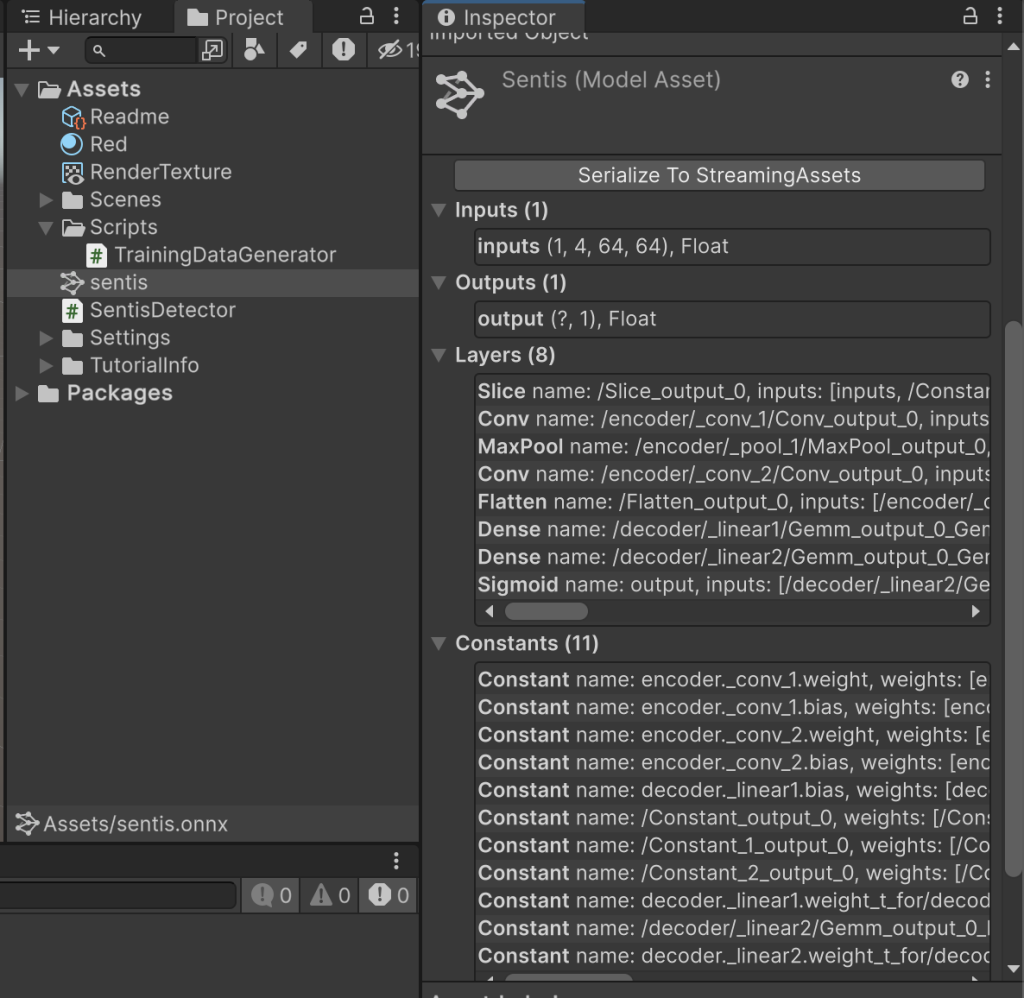
まず、ONNXファイルをUnityのProjectウィンドウにドラッグ&ドロップすることでSentisモデルアセットをロードします。ロードに成功すると、Projectウィンドウ内にsentisアセットが表示され、インスペクタでそのネットワーク構造の概要を確認できます。
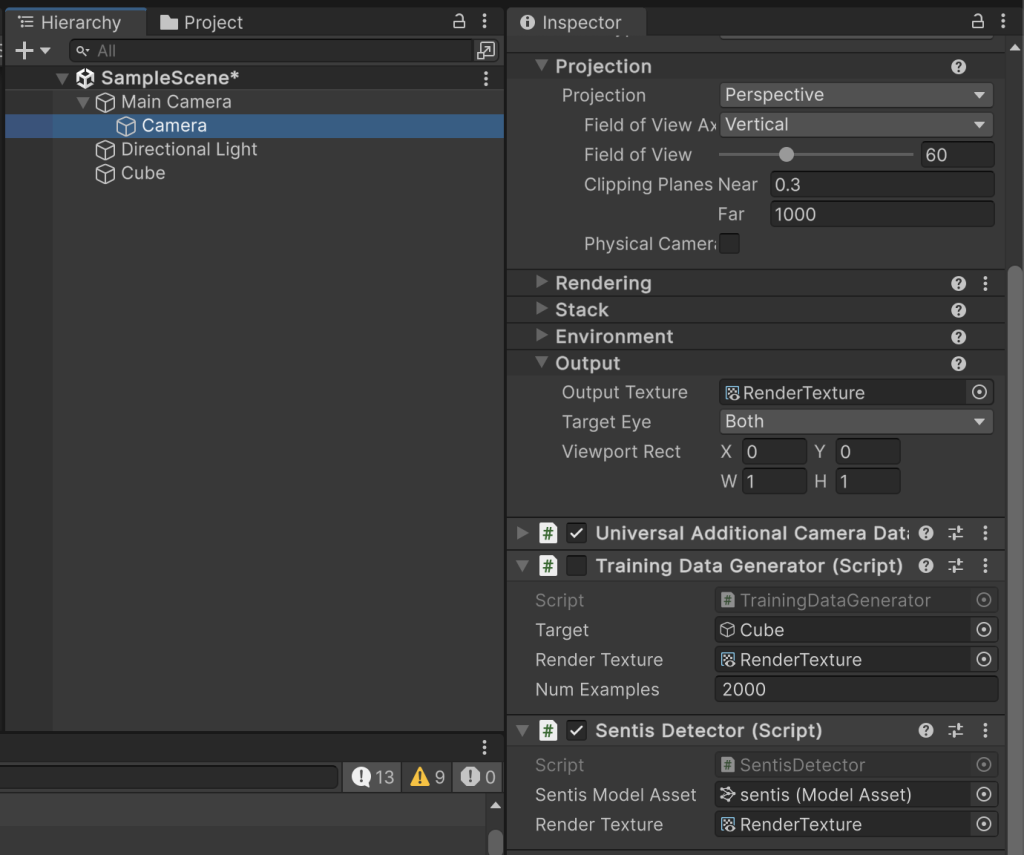
次に、子カメラ(Camera)にSentisDetector.csを追加します。その際、TrainindDataGeneratorコンポーネントはチェックマークを外すことで非アクティブにしておきます。そして、SentisDetectorコンポーネントのSentisModelAsset欄にはロードしたsentisアセットを、RenderTexture欄にはRenderTextureをセットします。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 | using UnityEngine; using Unity.Sentis; public class SentisDetector : MonoBehaviour { // Sentisモデルアセット [SerializeField] ModelAsset _sentisModelAsset; // 検出器への入力画像となるrender texture [SerializeField] RenderTexture _renderTexture; // ランタイムモデル Model _sentisRuntimeModel; // 推論エンジン IWorker _engine; void Start() { // ランタイムモデルと推論エンジンの初期化 _sentisRuntimeModel = ModelLoader.Load(_sentisModelAsset); _engine = WorkerFactory.CreateWorker(BackendType.GPUCompute, _sentisRuntimeModel); } public void Execute() { // render textureを入力テンソルに変換 TensorFloat inputTensor = TextureConverter.ToTensor(_renderTexture); // 推論の実行 _engine.Execute(inputTensor); inputTensor.Dispose(); // 出力テンソルの取得 TensorFloat outputTensor = _engine.PeekOutput() as TensorFloat; outputTensor.MakeReadable(); // テンソルデータをC#配列に変換 float[] results = outputTensor.ToReadOnlyArray(); outputTensor.Dispose(); // 可視性判定結果:シグモイド関数の出力値の取得 bool visible = results[0] >= 0.5f; Debug.Log($"Result: {visible.ToString()}"); } void Update() { if (Input.GetKeyDown(KeyCode.J)) { Execute(); } } private void OnDestroy() { _engine.Dispose(); } } |
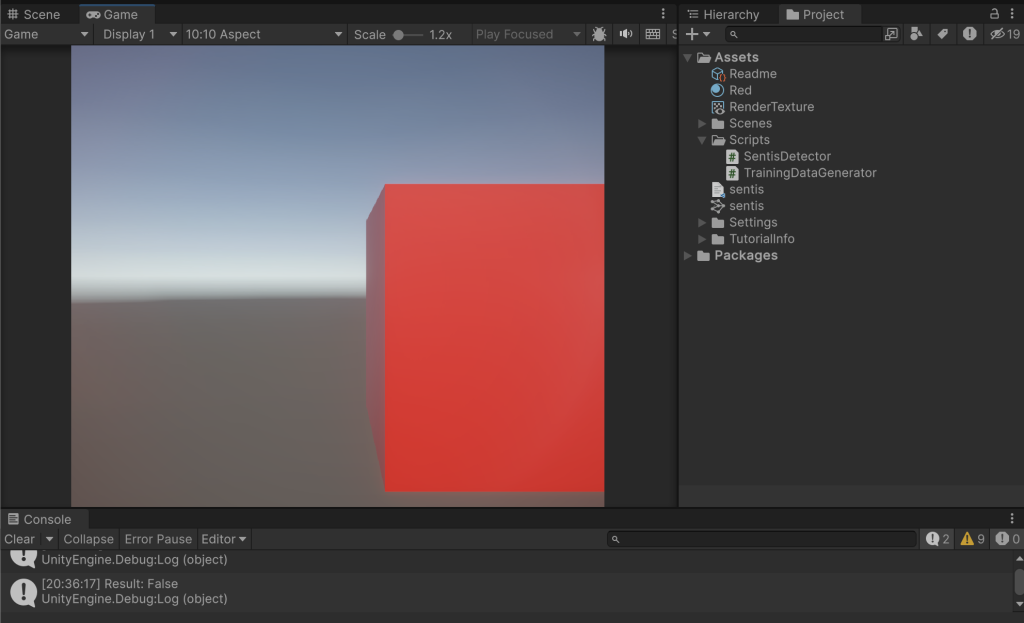
以上で設定は完了です。Unityを実行し、カメラや立方体を動かしながらキーボードの J キーを押すと判定結果がコンソールに出力されます。下図の例では立方体が少し右端からはみ出ていますので、False(全体が表示されていない)と判定されています。
まとめ
Unity Sentisプレビュー版を用いて簡単な画像分類器を実装してみました。UnityとPyTorch/TensorFlowに慣れている方であれば、非常に簡単に導入できると思います。公式レポジトリでも様々なサンプルが公開されていますので、色々試されると良いと思います。
今後はパフォーマンス計測(PyTorchとの比較)、ビルド時の挙動(windowsビルドでGPUは適切に利用されるか?)、ネットワークパラメータ数の上限などについても検証していきたいと思います。